
How to Create Your First Hugging Face Dataset
Aug 12, 2024
Modern AI tooling is mainly based on building models trained by lots of data rather than developing clever algorithms. This means that once you move beyond the basics of calling models others have developed and want to start training your own models, you'll need some data to do that training with.
Let's say that we are building a chatbot that emulates the speaking cadence of Darth Vader. We want to give cryptic answers to questions and intersperse our sentences with [kkchch] and [hhhssskk] breathing sounds.
In order to train the LLM behind this chatbot (future post), we've created a set of 100 questions/responses of the style in which the response should be given.
Here's the file we'll be using: vader.json
We need to put the data somewhere so that it's accessible by our team when they begin the training. So we decide to store the data in a Hugging Face Dataset.
Set Everything Up
There are several different data formats available on Hugging Face. They are pretty much what you're used to if you've dealt with data in software development: CSV (.csv, .tsv), JSON Lines or JSON (.jsonl, .json), Parquet (.parquet), and several others.
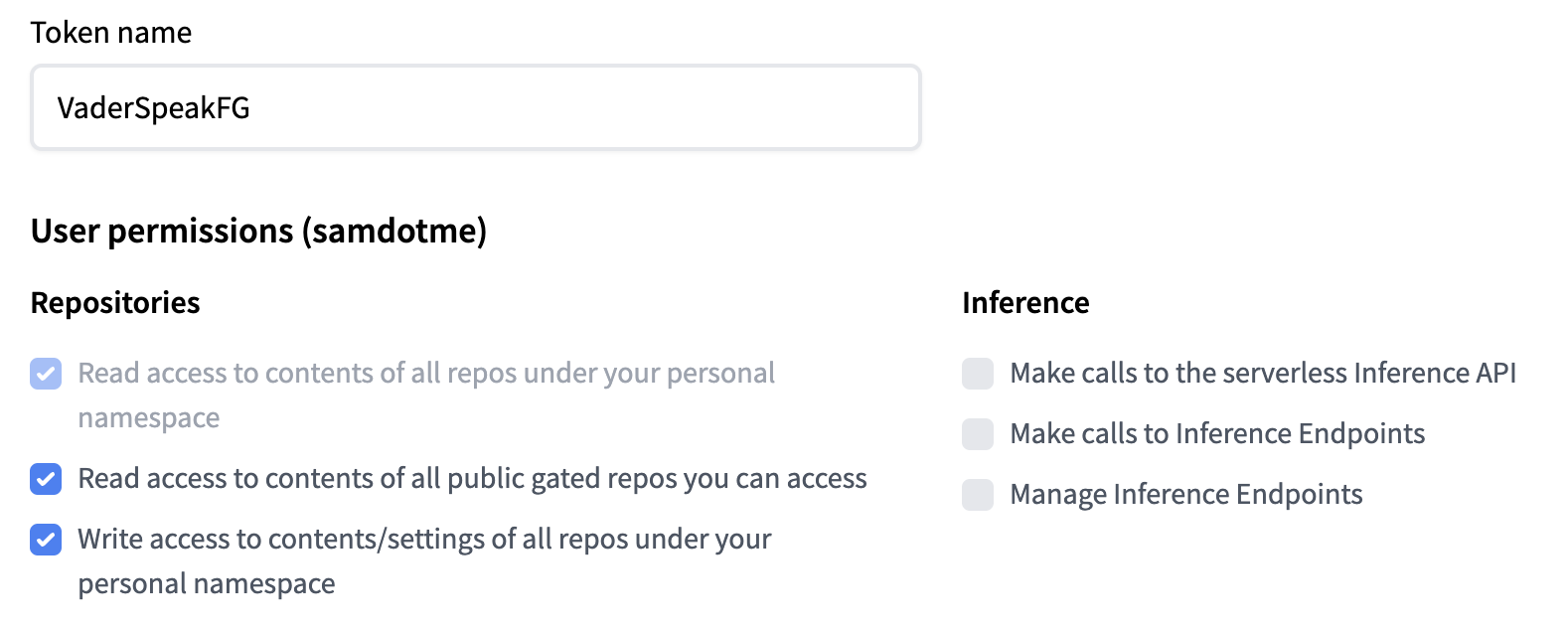
To follow along with this example, you'll first need to get set up with a Jupytr notebook (see my post on working with Google Colab notebooks) You'll also need to create a Hugging Face token which has write access to your repositories. Take a look at the image below for the permissions you'll need and also my post on creating a Hugging Face API token for detailed token creation steps.
First, let's load the file itself into the notebook and make sure we can pull the first item. Download the json file from the Git repository (right click on this file download link and choose "Save link as").
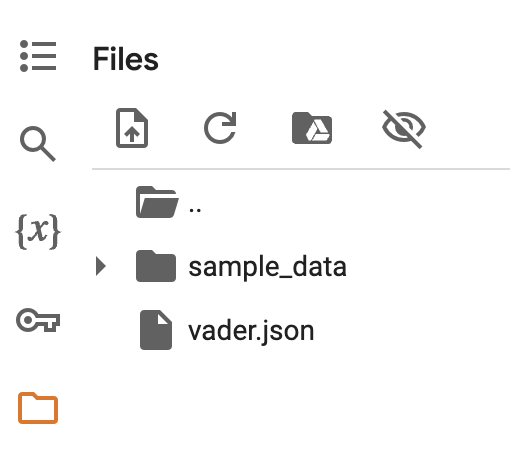
Then open the files tab in the Google Colab notebook.

Drag the file you just downloaded into the files area. It should now look like this:
Start Coding
Create and run the following code blocks in your notebook:
!pip install datasets huggingface_hubfrom datasets import load_dataset
dataset = load_dataset('json', data_files='vader.json')
print(dataset['train'][0])If you get something like this, things are up and running:
{'Q': 'Did you pay the electricity bill?', 'A': '[kkshhhh] The power of the dark side is enough [hhhkkshh]. We do not need bills [ppffffhhh].'}
Let's now create a dataset in your personal Hugging Face account. You can do that here: https://huggingface.co/new-dataset
I called mine vader-speak. You can check it out here: https://huggingface.co/datasets/samdotme/vader-speak
Now, in your notebook, add the following code block:
from huggingface_hub import notebook_login
notebook_login()This will pop open a login console where you can put in the token you created earlier.
Now, you just need to add another code block and input your repository name.
dataset.push_to_hub('[your-hugging-face-username]/[the-repository-name]')Go checkout your dataset on Hugging Face! You'll see a pretty cool dataset viewer.
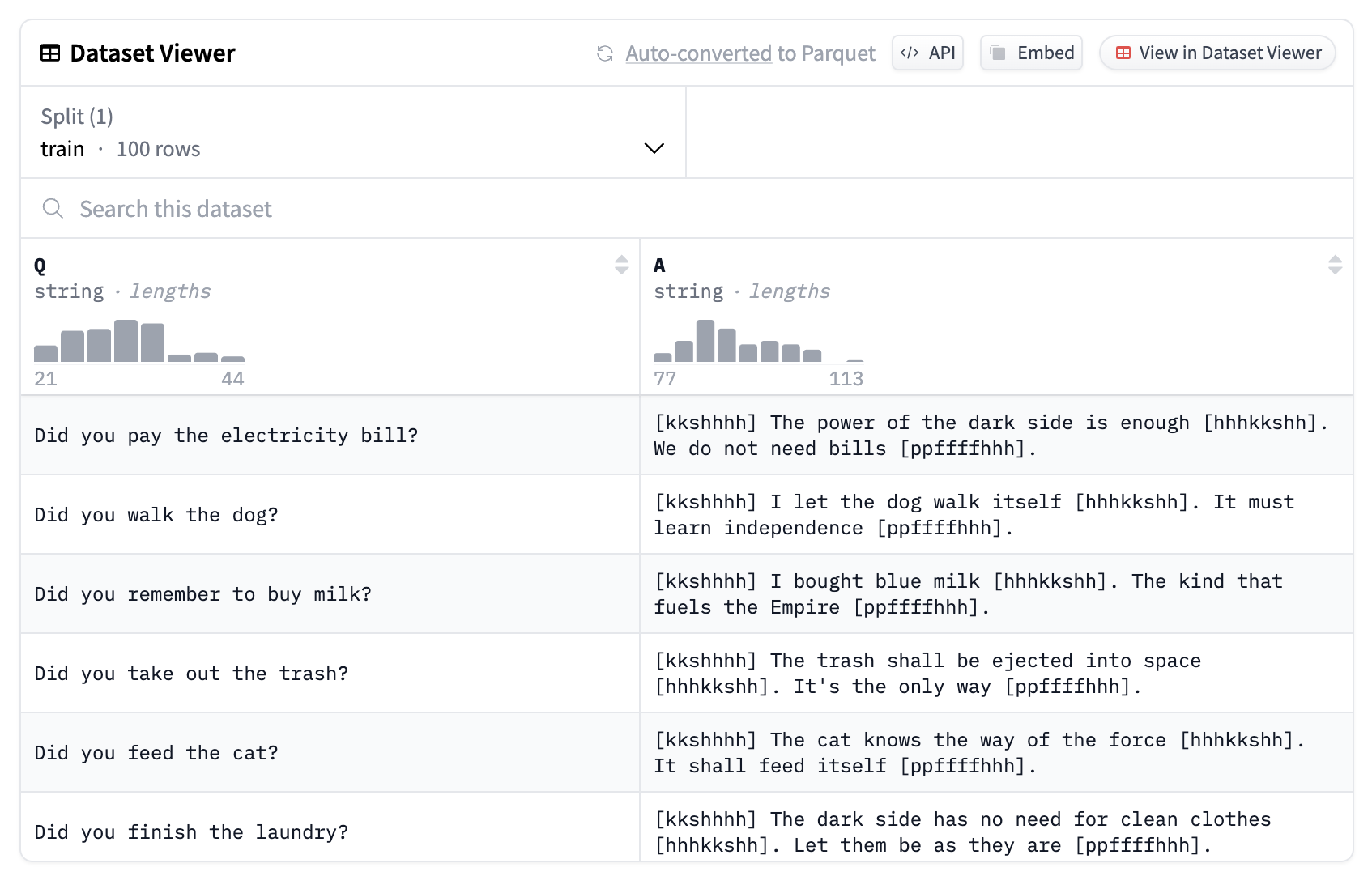
We can now use this data to fine-tune an LLM, which I'll be doing in the next post!
